
Artificial Intelligence (AI), is a decades-old field in computer science. Brad Myers, director of the Human-Computer Interaction Institute at Carnegie Mellon University, defines it as “a broad area of computer science that involves making machines behave in an intelligent way… It is sometimes said that AI is anything that we don’t yet know how to make computers do reliably, and once we do, it just becomes an algorithm and isn’t AI anymore.” In the 2020 United States Patent and Trademark Office (USPTO) report on AI, the office emphasized that “Undue effort should not be expended on defining AI, which is dynamic and will be subject to fundamental change in the coming years.” Since that report, a new generation of AI has made the Silicon Valley hype circuit: generative AI.
According to Dr. Alex Hanna, director of research at the Distributed AI Research Institute, “The current era of AI is pretty much focusing… exclusively on generative AI, which isn’t particularly new. There’s some new techniques being used.” Hanna says this generation of AI is based on deep learning and neural networks, which are inspired by an admittedly false conception of how the human brain works. There are two kinds of models: discriminative models which output a classification or discrete numerical prediction based on inputs, and generative models which do the inverse, namely generate outputs (like text or images) based on some input.
On a practical matter, the current crop of AI models primarily use large language models (LLMs). According to Hanna, LLMs “are a very souped-up auto-complete.” On a technical level, “they operate and make… some assumptions on outputs based on what’s in their training data… They are effectively making some kind of prediction across what is in their training data.” Given a prompt, the model makes a statistical prediction on the most likely response, and word-by-word generates an output.
And, as admitted by OpenAI, long-form high-quality copyrighted prose, such as books and New York Times articles are essential data. In an evidence filing before the House of Lords in the United Kingdom, the company behind ChatGPT said, “It would be impossible to train today’s leading AI models without using copyrighted materials … Limiting training data to public domain books and drawings created more than a century ago might yield an interesting experiment, but would not provide AI systems that meet the needs of today’s citizens.”
The reason for this, Dr. Hanna explains, is that the models only work if they are trained on data that looks like how people write to each other. “If you want something that looks legible, that looks more like a New York Times article, it needs longer form text.”
The USPTO Report on AI
In the latter half of 2019, the USPTO issued a pair of requests for comment on AI and Intellectual Property issues. On October 7, 2020, they released a report summarizing the comments. Among discussions around patentability and whether AI can own intellectual property, the report includes a lengthy discussion around copyright issues.
In responding to commenters acknowledging that AI models would have to “ingest” large quantities of copyrighted material, the USPTO stated, “Existing statutory and case law should adequately address the legality of machine ‘ingestion’ in AI scenarios. Mass digitization and text and data mining (TDM), as relevant examples of other activities with copyright implications, may be considered copyright infringement or fair use, depending on the facts and circumstances at issue.… Copying substantial portions of expressive (copyrighted) works, even for non-expressive purposes implicates the reproduction right and, absent an applicable exception, is an act of copyright infringement.”
The News Media Alliance commented, “Tech platforms that appropriate vast quantities of news content for this purpose should pay for the privilege of doing so, no less than they should pay for the privilege of doing so, no less than they should pay for the electricity that powers their computers or motorists for the fuel that powers their cars.” Other commenters debated whether ingestion might fall under “fair use,” and whether copyright law might be amended to allow AI to be trained free from copyright liability to “promote innovation.”
The USPTO further emphasized that “If the AI’s owner takes sufficient action to cause the AI’s infringement—through programming, data inputs, or otherwise—the owner could directly or contributorily infringe.” Conversely, multiple commenters discussed that courts will have to consider novel issues of whether AI companies contributorily and/or vicariously infringe upon copyright holders’ rights, by allowing their users to potentially infringe on said copyrights.
Copyright Litigation in the AI Industry
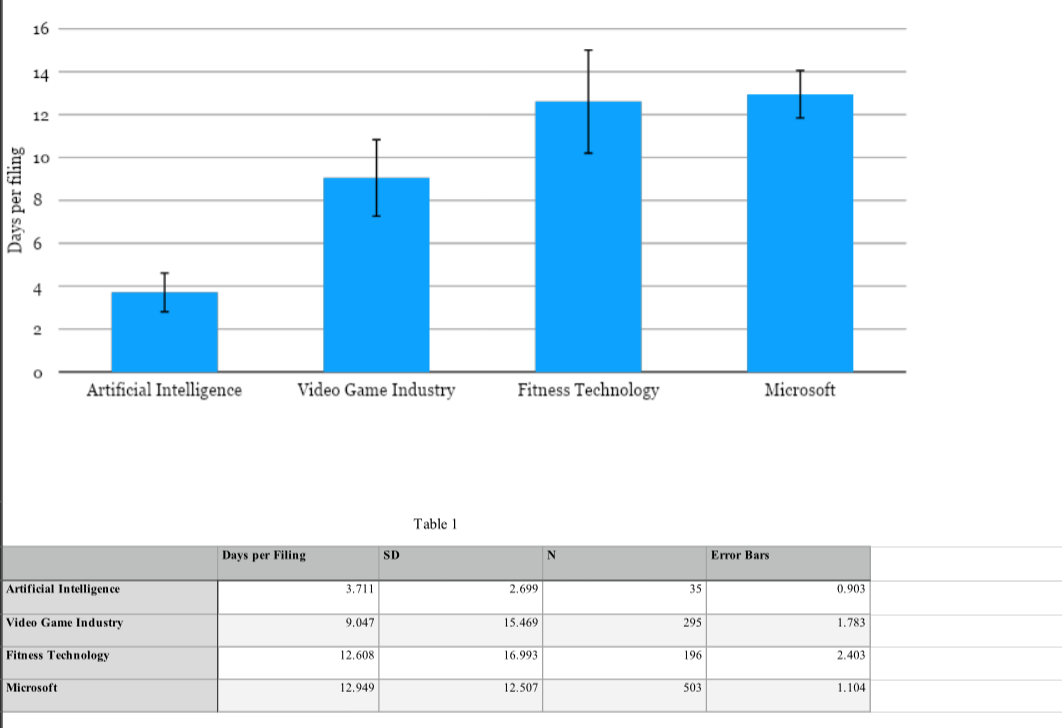
Since October 2022, the AI industry has seen thirty-five suits, eighteen of which concern alleged copyright infringement. Across the board, however, the litigation has been intense, with an average of 3.7 days passing between each filing. For perspective, Microsoft averaged 13.0 days per filing, the video game industry 9.0 days per filing, and the fitness technology industry 12.6 days per filing.
DOE 1 et al v. GitHub, Inc. et al
On November 3, 2022, two anonymous individuals sued GitHub, OpenAI, and Microsoft over alleged copyright infringement by GitHub’s Copilot coding assistant. A week later, three other anonymous individuals followed suit, though their cases were consolidated into the former. The complaint details the history of GitHub as an open-source repository for code. However, open-source, the plaintiffs say, does not mean free to use. “Use of the Licensed Materials requires some form of attribution, usually by, among other things, including a copy of the license along with the name and copyright notice of the original author.”
As will be a theme with AI litigation, the plaintiffs allege that their copyrights were infringed when the defendants used their work as training data for a generative AI tool, in this case, GitHub’s Copilot.

As evidence, the plaintiffs present numerous examples of Copilot directly copying users’ code without providing citations or the copyright information of the code in question. In one instance, Copilot provided code that contained extraneous lines that tested whether the code in question worked. However, one line in the addendum is nonsensical, “???” is a nonsense term in this coding language; it exists as a problem for the reader to solve; the copied code came from a textbook exercise.
The plaintiffs allege numerous charges, though they rely heavily on the Digital Millenium Copyright Act (DMCA), which as is relevant here, prohibits the modification or removal of copyright information from a work.
On June 24, 2024, Judge Tigar partially dismissed the second amended complaint. He ruled in favor of the defendants’ motion to dismiss the DMCA claims on the grounds that Copilot’s output is not identical to the copyrighted material, and thus did not violate the DMCA provisions regarding removing or altering copyright information. The court also dismissed the plaintiffs’ unjust enrichment charge. The case is proceeding around whether GitHub and OpenAI committed breach of contract by allegedly violating the open-source license.
OpenAI in the Northern District of California (NDCA)
On June 28, 2023, Paul Tremblay and Mona Awad sued OpenAI for copyright infringement. In the following months, numerous copycat suits were also filed in the NDCA and were eventually consolidated into a single suit titled In re OpenAI Litigation. The plaintiffs, a collection of authors, allege that OpenAI used their books as training data for the latest version of General Purpose Transformer (GPT), the company’s generative AI model.
Specifically, the plaintiffs allege that their works are included in the dataset OpenAI labeled as Books2. While the contents of this dataset are unknown, based on its size, the plaintiffs infer that it is sourced from one of a number of illegal book torrenting websites.
In the original complaints, the plaintiffs alleged direct copyright infringement, vicarious copyright infringement, modifying and removing copyright information under the DMCA, unfair competition under California state law, and negligence and unjust enrichment under common law. OpenAI moved to dismiss all but the direct copyright infringement claim.
On February 2, 2024 Judge Araceli Martínez-Olguín narrowed the case. She dismissed the vicarious copyright infringement, DMCA, negligence, and unjust enrichment claims, the first two with leave to amend. Regarding the vicarious copyright infringement claims, Judge Martínez-Olguín ruled that the plaintiffs had not pled that ChatGPT users reproduce copies of the plaintiffs’ work, nor did they adequately allege that ChatGPT outputs are substantially similar. Judge Martínez-Olguín dismissed the DMCA claims under two grounds. First, she ruled that the plaintiffs had not pled that ChatGPT removes copyright information, since the outputs presented as evidence contain references to the plaintiffs’ original work. Second, she ruled that even if OpenAI removed copyright information, the plaintiffs “have not shown how omitting CMI in the copies used in the training set gave Defendants reasonable grounds to know that ChatGPT’s output would induce, enable, facilitate, or conceal infringement.”
“Plaintiffs compare their claim to that in [DOE 1 et al v. GitHub, Inc. et al], however, the plaintiffs in Doe 1 alleged that the defendants “distributed copies of [plaintiff’s licensed] code knowing that CMI had been removed or altered.”
The other dismissed claims were done so on similar grounds. The plaintiffs submitted an amended complaint containing only the direct copyright infringement and the unfair competition claims. The case will proceed centered around OpenAI allegedly copying the plaintiffs’ books without license to train various iterations of GPT.
Of particular note, after a pretrial schedule was set, OpenAI moved to intervene from the case cluster in the Southern District of New York. Judge Martínez-Olguín ruled that OpenAI was forum shopping to attain a more favorable schedule and denied the motion.
OpenAI in the Southern District of New York (SDNY)
Like in the NDCA, numerous authors, including George R. R. Martin, have sued OpenAI for allegedly infringing their copyrights. These have been consolidated into Authors Guild et al v. OpenAI Inc. et al, a case originally filed in September 2023, and as of the writing of this article, has seen 215 filings.
In addition to the usual claims around OpenAI illegally copying the plaintiffs’ work for “ingestion” by various iterations of GPT, the authors allege that OpenAI is stealing authors’ income, specifically that of journalists.
“As a result of embedding our writings in your systems, generative AI threatens to damage our profession by flooding the market with mediocre, machine-written books, stories, and journalism based on our work…. The introduction of generative AI threatens… to make it even more difficult, if not impossible, for writers—especially young writers and voices from under-represented communities—to earn a living from their profession.”
As evidence, the plaintiffs present examples of Chat GPT generating unauthorized summaries of nonexistent sequels in the authors’ various serieses. They do not explain how these GPT creations differ from fan fiction.
Of particular note, on March 4, 2024, the plaintiffs in re OpenAI Litigation filed a motion to intervene to dismiss, stay, or consolidate this case into the NDCA. Judge Sidney Stein ruled that the two cases are substantially different and that since no classes have been certified, the cases should continue separately. She similarly dismissed the motion to intervene in The New York Times Company v. Microsoft Corporation et al. The NDCA plaintiffs have appealed these decisions to the Second Circuit.
The case is currently going through discovery.
The New York Times Company v. Microsoft Corporation et al
On December 27, 2023, the New York Times sued OpenAI and Microsoft, which owns a substantial stake in OpenAI and hosts their processing on the Azure servers. The Times makes many of the same allegations as plaintiffs in the other copyright suits against the two companies; however, the New York Times emphasizes their value in the training data and elaborates on how exactly ChatGPT’s and Bing Chat’s alleged infringement financially damages the paper.
First, The Times expounds on their importance in the data used to train early versions of GPT. According to the complaint, the New York Times domain is the third most skimmed domain in the Common Crawl dataset, the heaviest-weighted dataset in GPT-3.0’s training.

Second, the Times provides multiple examples of GPT-4 replicating near-verbatim passages from New York Times articles. The complaint goes on to show prompts to Chat GPT and Bing Chat returning exact paragraphs from New York Times articles. The paper explains how this allows users to circumvent the paywall they rely on to continue to provide “the public with independent journalism of the highest quality.”
The New York Times case is the only one thus far to litigate a known design flaw in many AI tools: hallucinations. In short, AI chatbots have been known to occasionally provide nonsense or factually incorrect information when prompted. For example, Gemini, Google’s generative AI search tool, famously told users that geologists at UC Berkeley recommend eating “at least one small rock per day”; it cited an Onion article.
The complaint details multiple examples of Bing Chat and ChatGPT fabricating information in New York Times articles. For example, GPT-4 concocted Wirecutter recommending office chairs it did not even review. Bing Chat allegedly invented quotes attributed to Steve Forbes’s daughter Moira Forbes that she never said and were never included in the original New York Times article. The “paper of record” argues these hallucinations damage their reputation.
Discovery is ongoing, and on October 4, 2024, OpenAI and Microsoft filed a motion to consolidate this case and other similar cases filed by other newspapers and the Center for Investigative Reporting.
Andersen et al v. Stability AI Ltd. et al
On January 13, 2023, a group of artists sued Stability AI; Midjourney, DeviantArt, and Runway AI over copyright infringement. They allege the companies illegally copied their art to train their image-from-prompt tools.
These tools are based on a few different algorithms. For the image generation itself, the tools use diffusion models.
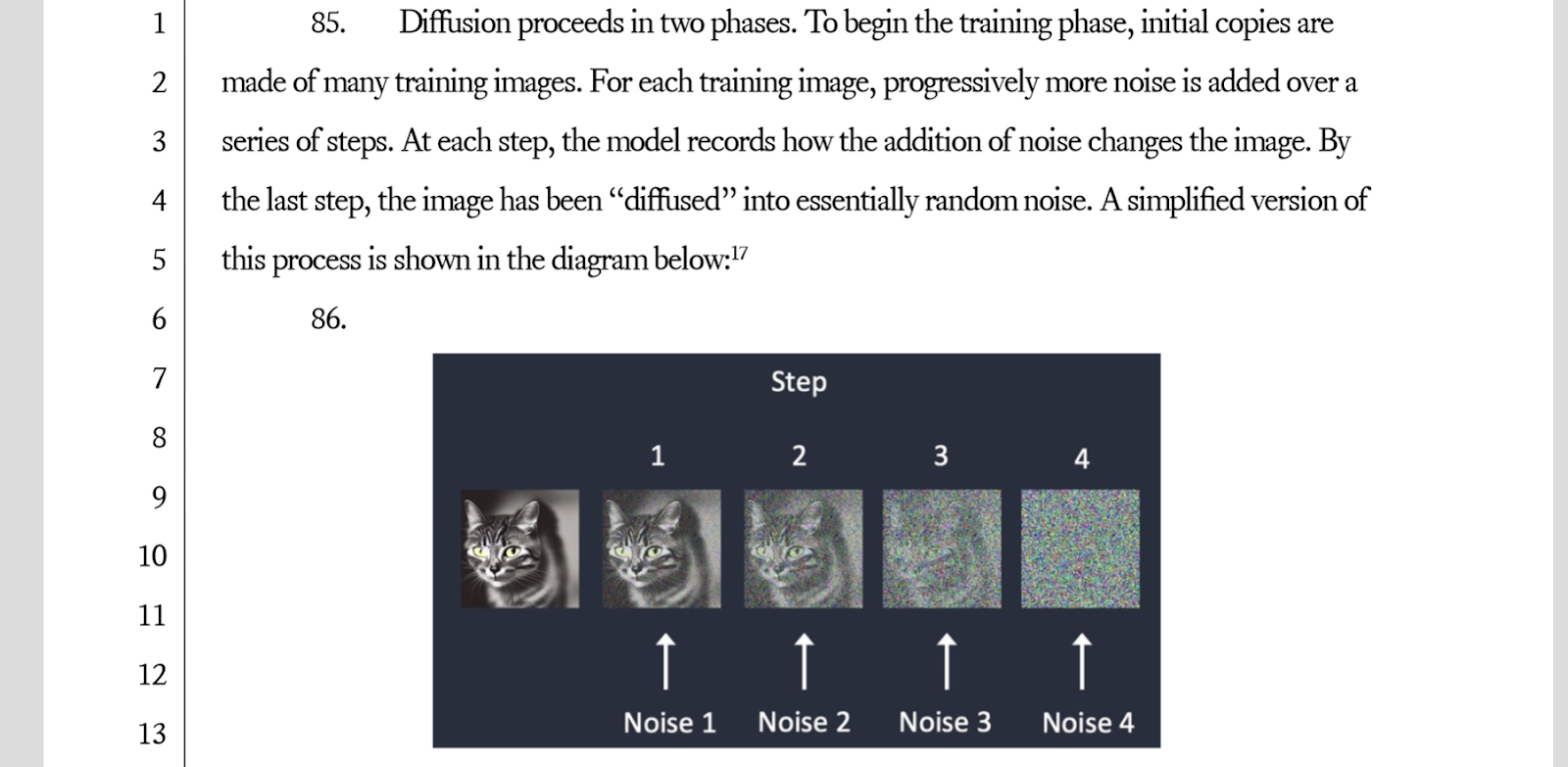
According to the amended complaint, diffusion models are trained by copying pictures and then changing pixels until the image becomes noise. Once the model is trained, it then reverses this process to create new images. These models are then supplemented by contrastive language–image pretraining (CLIP). CLIP models correlate images and captions. The plaintiffs allege that the defendants used datasets called Large-Scale Artificial Intelligence Open Network-400M and -5B (LAION). LAION-400M and -5B contain URL links to 400 million and 5 billion images respectively, as well as captions for each image. Dr. Hannah says that often these captions are created for accessibility.
In sum, when a prompt is entered the CLIP model analyzes the text and predicts the most likely image to pair with said prompt, and then the diffusion model creates the image.

As to the alleged copyright infringement, the plaintiffs allege that AI image generation companies illegally copied their works for use in training, then recreate their images, or infringing derivative works of their images, whenever a user prompts the tools with the plaintiffs’ name. As evidence, the artists present their original images alongside images created by Stable Diffusion that bear striking similarities.
The plaintiffs charge direct copyright infringement by copying their art in training the AI tools, induced copyright infringement by inducing users to infringe the artists’ copyrights in using said tools, DMCA violations by removing artists’ watermarks in creating copies and/or infringing derivative works, unjust enrichment, and false endorsement and vicarious trade-dress violation under the Lanham Act for all of the above. Regarding the last two, the plaintiffs point to a list published by Midjourney CEO David Holz on Discord that lists hundreds of artists whose style Midjourney can presumably mimic. Plaintiffs also allege breach of contract against DeviantArt for using their images as part of its use of Stability AI.
On August 12, 2024, Judge William Orrick narrowed the case. He dismissed the plaintiffs’ DMCA claims against Stability as the works produced by the defendant are not direct copies, agreeing with Judge Tigar in DOE 1 et al v. GitHub, Inc. et al. The unjust enrichment claims against Stability were dismissed as being preempted by the plaintiffs’ copyright claims. Judge Orrick dismissed the DMCA claims against other defendants on similar grounds. Finally, he dismissed the breach of contract claims against DeviantArt. The case is proceeding with the remainder of the charges.
Concord Music Group, Inc. et al v. Anthropic PBC
On October 18, 2023, Concord Music Group and a slew of other music publishers sued Anthropic for copyright infringement. They allege that the company illegally scraped song lyrics as training data. The case was originally filed in the Middle District of Tennessee but has since been transferred to the NDCA.
As is the trend in this new vein of litigation, the music publishers emphasize in their complaint that “publicly available” does not mean license-free. As an example, the plaintiffs explain that there are several song lyrics aggregator websites; however, those sites obtain licenses from the publishers and list important copyright information alongside the lyrics such as the songwriters, composers, publisher, and other important personages.
And, like in the other suits, the plaintiffs in this suit list numerous examples of Anthropic’s Claude AI reproducing song lyrics without providing the requisite, the publishers say, copyright information. Furthermore, when the plaintiffs prompted Claude to generate lyrics to a new song about the death of Buddy Holly, Claude generated lyrics containing many of the same lines as Don McLean’s “American Pie.”
The production companies charge Anthropic with direct copyright infringement, contributory copyright infringement, vicarious copyright infringement, and removal of copyright information under the DMCA.
Unique to other AI suits at this stage, numerous entities have filed Amicus briefs. The Chamber of Commerce and Netchoice have submitted briefs in favor of Anthropic, and the Association of American Publishers, Inc., the Black Music Action Coalition, the National Music Publishers Association, the News/Media Alliance, the Recording Industry Association of America, Songwriters of North America, Artist Rights Alliance, the American Association of Independent Music, and the Music Artists Coalition submitted briefs in favor of the music publishers.
The parties are currently litigating the plaintiffs’ motion for an injunction and the defendants’ motion to dismiss.
Other suits of note
On August 2, 2024, David Milette sued both OpenAI and Google over the companies scraping transcripts of YouTube videos for training data for GPT and Gemini respectively.
Not long after the filing of Andersen et al v. Stability AI Ltd. et al, Getty Images similarly sued Stability AI.
Musk v. Altman et al
On August 8, 2024, Elon Musk filed suit against Sam Altman, Gregory Brockman, and OpenAI’s myriad of corporate entities. In a complaint riddled with strains of longtermism, the controversial billionaire asserts that Sam Altman and Gregory Brockman led him in with promises that OpenAI, which Elon Musk named, would be an open-source nonprofit for the good of humanity, but once Musk’s seed investment had borne fruit, the complaint describes how the two spun off various for-profit entities littered with self-dealing. In essence, OpenAI is now a de facto for-profit company, though investors’ profits are capped at 100x, a limit so high it is practically nonexistent. That said, Sam Altman has made moves in recent months to remove that cap.
Editor’s Note: Brad Myers, cited at the beginning of this article, is related to the author of this article. However, Myers was not interviewed for the article.
